
Character support
When defining the message body in your request, both the character set and message length impact the number of SMS segments sent. If you use personalization (Liquid Syntax), message length can vary per recipient based on their specific data.
The characters used also influence the encoding format. The API automatically detects the required encoding based on the content, ensuring support for SMS delivery in any language.
A single SMS message can contain up to 160 characters, provided all characters used belong to the GSM 7-bit character set.
Naxai technically allows messages of up to 2000 characters across all messaging channels, including SMS. However, very long SMS messages can harm both deliverability and the overall user experience. This is because SMS relies on message segmentation, a process that splits long messages into multiple parts, which also increases the total cost.
For best performance and predictable pricing, Naxai recommends keeping SMS content to 320 characters or fewer.
Counting characters in Naxai Web Interfaces
When counting characters in the different modules like Quick SMS, SMS Broadcasts ..., we display the number of characters and the SMS parts represented as follows:
When the text is known and less than 160 characters or 70 characters, the information appears in gray.

When the message is greater than 1 SMS part, we display the message in yellow
When you reach the maximum number of characters (2000 for text), we display the information in red.
When a placeholder (Liquid Syntax) is used, we use the same colors but add a tilde (~) in front of the text, indicating the size is estimated. If you want to avoid sending messages greater than 1 or 2 SMS parts, you can use the advanced options to limit the number of parts.

GSM-7 alphabet and Unicode
The GSM-7 character set consists of both basic and extended characters. The image below displays the basic characters on the left and the extended ones on the right.
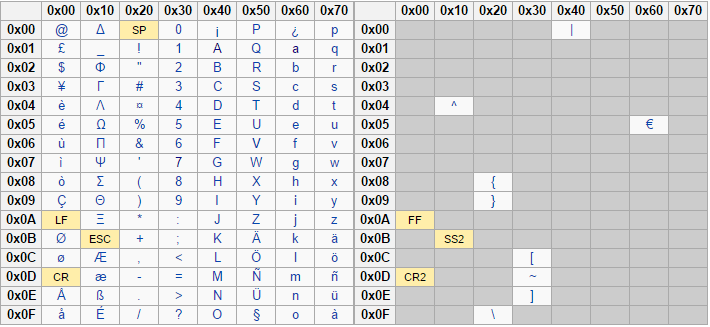
Extended Character Set
The following characters are also available, but they're counted as two characters in the SMS message rather than one:
| , ^ , € , { , } , [ , ] , ~ , \
Transliteration of characters
When using Text, the Naxai Platform will try to replace all characters having an equivalent in the transliteration table.
Some characters, such as double quotes, have different formats, including the left-pointing double angle quotation mark, left double quotation mark, modifier letter double prime, and double high-reversed-9 quotation mark. These special double quotes are replaced by the standard double quotes.
{
"’": "'",
" ": " ",
"\t": " ",
"\f": " ",
"¢": "c",
"¦": "|",
"¨": " ",
"˛": ",",
"©": " ",
"ª": " ",
"«": "\"",
"¬": "-",
"®": " ",
"¯": " ",
"°": " ",
"±": " ",
"²": " ",
"³": " ",
"`": "'",
"µ": " ",
"¶": " ",
"·": " ",
"¸": " ",
"¹": " ",
"º": " ",
"»": "\"",
"À": "A",
"Á": "A",
"Â": "A",
"Ã": "A",
"È": "E",
"Ê": "E",
"Ë": "E",
"Ì": "I",
"Í": "I",
"Î": "I",
"Ï": "I",
"Ð": "D",
"Ò": "O",
"Ó": "O",
"Ô": "O",
"Õ": "O",
"×": "x",
"Ù": "U",
"Ú": "U",
"Û": "U",
"Ý": "Y",
"Þ": "b",
"á": "a",
"â": "a",
"ã": "a",
"ê": "e",
"ë": "e",
"í": "i",
"î": "i",
"ï": "i",
"ð": "o",
"ó": "o",
"ô": "o",
"õ": "o",
"ú": "u",
"û": "u",
"ý": "y",
"þ": "b",
"ÿ": "y",
"ç": "Ç",
"“": "\"",
"”": "\"",
"ʺ": "\"",
"ˮ": "\"",
"‟": "\"",
"❝": "\"",
"❞": "\"",
"〝": "\"",
"〞": "\"",
""": "\"",
"‘": "'",
"'": "'",
"ʻ": "'",
"ˈ": "'",
"ʼ": "'",
"ʽ": "'",
"ʹ": "'",
"‛": "'",
"'": "'",
"´": "'",
"ˊ": "'",
"ˋ": "'",
"❛": "'",
"❜": "'",
"̓": "'",
"̔": "'",
"︐": "'",
"︑": "'",
"÷": "/",
"¼": "1/4",
"½": "1/2",
"¾": "1/3",
"⧸": "/",
"̷": "/",
"̸": "/",
"⁄": "/",
"∕": "/",
"/": "/",
"⧹": "\\",
"⧵": "\\",
"◌⃥": "\\",
"﹨": "\\",
"\": "\\",
"̲": "_",
"_": "_",
"⃒": "|",
"⃓": "|",
"∣": "|",
"|": "|",
"⎸": "|",
"⎹": "|",
"⏐": "|",
"⎜": "|",
"⎟": "|",
"⎼": "-",
"⎽": "-",
"―": "-",
"﹣": "-",
"-": "-",
"‐": "-",
"•": "-",
"⁃": "-",
"﹫": "@",
"@": "@",
"﹩": "$",
"$": "$",
"ǃ": "!",
"︕": "!",
"﹗": "!",
"!": "!",
"﹟": "#",
"#": "#",
"﹪": "%",
"%": "%",
"﹠": "&",
"&": "&",
"‚": ",",
"̦": ",",
"﹐": ",",
"、": ",",
"﹑": ",",
",": ",",
"、": ",",
"❨": "(",
"❪": "(",
"﹙": "(",
"(": "(",
"⟮": "(",
"⦅": "(",
"❩": ")",
"❫": ")",
"﹚": ")",
")": ")",
"⟯": ")",
"⦆": ")",
"⁎": "*",
"∗": "*",
"⊛": "*",
"✢": "*",
"✣": "*",
"✤": "*",
"✥": "*",
"✱": "*",
"✲": "*",
"✳": "*",
"✺": "*",
"✻": "*",
"✼": "*",
"✽": "*",
"❃": "*",
"❉": "*",
"❊": "*",
"❋": "*",
"⧆": "*",
"﹡": "*",
"*": "*",
"˖": "+",
"﹢": "+",
"+": "+",
"。": ".",
"﹒": ".",
".": ".",
"。": ".",
"0": "0",
"1": "1",
"2": "2",
"3": "3",
"4": "4",
"5": "5",
"6": "6",
"7": "7",
"8": "8",
"9": "9",
"ː": ":",
"˸": ":",
"⦂": ":",
"꞉": ":",
"︓": ":",
":": ":",
"⁏": ";",
"︔": ";",
"﹔": ";",
";": ";",
"﹤": "<",
"<": "<",
"͇": "=",
"꞊": "=",
"﹦": "=",
"=": "=",
"﹥": ">",
">": ">",
"︖": "?",
"﹖": "?",
"?": "?",
"A": "A",
"ᴀ": "A",
"B": "B",
"ʙ": "B",
"C": "C",
"ᴄ": "C",
"D": "D",
"ᴅ": "D",
"E": "E",
"ᴇ": "E",
"F": "F",
"ꜰ": "F",
"G": "G",
"ɢ": "G",
"H": "H",
"ʜ": "H",
"I": "I",
"ɪ": "I",
"J": "J",
"ᴊ": "J",
"K": "K",
"ᴋ": "K",
"L": "L",
"ʟ": "L",
"M": "M",
"ᴍ": "M",
"N": "N",
"ɴ": "N",
"O": "O",
"ᴏ": "O",
"P": "P",
"ᴘ": "P",
"Q": "Q",
"R": "R",
"ʀ": "R",
"S": "S",
"ꜱ": "S",
"T": "T",
"ᴛ": "T",
"U": "U",
"ᴜ": "U",
"V": "V",
"ᴠ": "V",
"W": "W",
"ᴡ": "W",
"X": "X",
"Y": "Y",
"ʏ": "Y",
"Z": "Z",
"ᴢ": "Z",
"ˆ": "^",
"̂": "^",
"^": "^",
"᷍": "^",
"❴": "{",
"﹛": "{",
"{": "{",
"❵": "}",
"﹜": "}",
"}": "}",
"[": "[",
"]": "]",
"˜": "~",
"˷": "~",
"̃": "~",
"̰": "~",
"̴": "~",
"∼": "~",
"~": "~",
"‗": "_",
"—": "-",
"-": "-",
"‹": ">",
"›": "<",
"‼": "!!",
"„": "\"",
"…": "...",
"": ""
}Other Characters
When characters outside the GSM set are needed, such as for non-Latin scripts, messages are encoded using 16-bit Unicode (UCS-2). Each character consumes 2 bytes in this format, limiting a single SMS to a maximum of 70 characters.
Long messages
The message body in a request can include up to 2000 characters. However, SMS messages have encoding limitations:
- GSM 7-bit encoding supports up to 160 characters per message.
- Unicode (UCS-2) encoding, used for non-GSM characters (e.g., emojis or non-Latin scripts), supports up to 70 characters per message.
- Additionally, each message includes a header that consumes part of the character limit.
To support longer texts, the system automatically splits messages into multiple segments. These segments are typically reassembled on the recipient’s device, appearing as continuous messages. Refer to the charts below to estimate how many SMS segments your message will require.
Maximum characters acceptedMessages exceeding 2000 characters will trigger a 422 error and will not be sent.
Using text, unicode or auto encoding
When sending messages, you can choose the encoding used.
Text
When text is used as encoding, all characters outside the basic and extended character will be evaluated.
Transliteration is applied if the character can be transliterated into another character.
For example: in French, the character ç will be replaced (transliterated) by Ç
If the character cannot be replaced via transliteration, then the character is replaced by a question mark ?
Unicode
When unicode is used, then all characters are accepted but the length of one SMS is limited to 70 characters.
Auto
When auto is used, we will use text or Unicode automatically, depending on the characters present in the message.
Length of messages
Using only 7-bit Characters
Each SMS in a multi-part 7-bit encoded message has a maximum length of 153 characters.
| Length of message | # SMS parts |
|---|---|
| 1–160 | 1 |
| 161–306 | 2 |
| 307–459 | 3 |
| 460–612 | 4 |
| 613–765 | 5 |
| 766–918 | 6 |
| 919–1071 | 7 |
| 1062–1224 | 8 |
| 1225–1377 | 9 |
| 1378–1530 | 10 |
| 1531-1683 | 11 |
| 1684-1836 | 12 |
| 1837-1989 | 13 |
| 1990-2000 | 14 |
Using Unicode
Each SMS in a multi-part Unicode-encoded message has a maximum length of 67 characters.
| Length of message | # SMS parts |
|---|---|
| 1 - 70 | 1 |
| 71 - 134 | 2 |
| 135 - 201 | 3 |
| 202 - 268 | 4 |
| 269 - 335 | 5 |
| 336 - 402 | 6 |
| 403 - 476 | 7 |
| 477 - 543 | 8 |
| 544 - 610 | 9 |
| 611 - 677 | 10 |
| 678 - 744 | 11 |
| 745 - 811 | 12 |
| 812 - 878 | 13 |
| 879 - 945 | 14 |
| 946 - 1079 | 15 |
| 1080 - 1146 | 17 |
| 1147 - 1213 | 18 |
| 1214 - 1280 | 19 |
| 1281 - 1347 | 20 |
| 1348 - 1414 | 21 |
| 1415 - 1481 | 22 |
| 1482 - 1548 | 23 |
| 1549 - 1615 | 24 |
| 1616 - 1682 | 25 |
| 1683 - 1749 | 26 |
| 1750 - 1816 | 27 |
| 1817 - 1883 | 28 |
| 1884 - 1950 | 29 |
| 1951 - 2000 | 30 |
Max length is set to 2000(*) Please note that sending more than 2000 characters in unicode will produce an error but 2000 characters will result in 30 SMS segments.
Updated 4 months ago